Classificação
A ciência de dados é a área da engenharia que se dedica a transformar dados em informação. Isto é feito através de um modelo de classificação que manipula conceitos, que representam os dados. De modo a criar um modelo que reconheça qualquer entidade, é necessário recolher exemplos dessa mesma entidade, bem como exemplos que não representem essa entidade (por exemplo, um pato e um pato de borracha).
Objetivo
O objetivo da classificação é, automaticamente, identificar o conjunto de variáveis satisfeitas por instanciações do conceito a aprender e que não são satisfeitas por outras entidades, as chamadas variáveis relevantes. Ao conseguir classificar entidades, com base nestas variáveis, o modelo consegue agora classificar a instância como pertencente a uma classe.
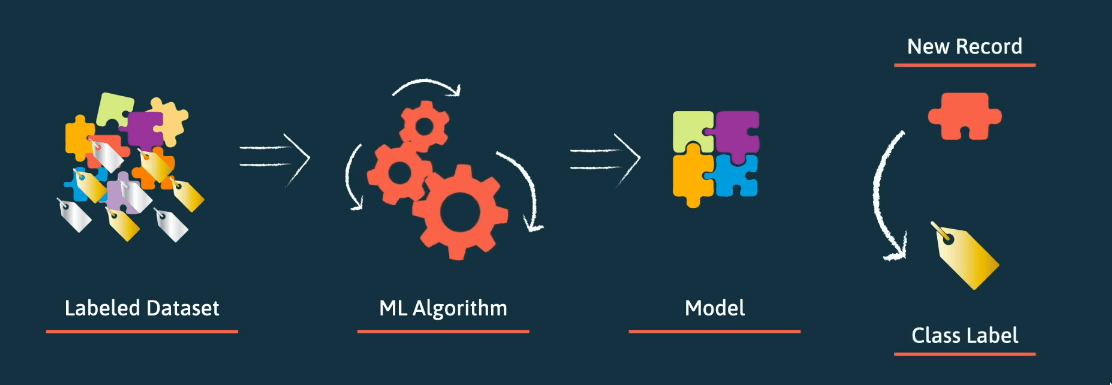
Labeled Dataset
Para aprender qualquer conceito, é necessário um conjunto de dados descrito por um número de variáveis de qualquer tipo, bem como uma variável simbólica, a classe ou rótulo, que nos indica a classe representada pelas variáveis. Chama-se a este conjunto de dados um labeled dataset, pois os dados são rotulados.

Modelo
Após fornecer um conjunto de dados de treino ao algoritmo de aprendizagem, este devolve um modelo. Dado um objeto, o modelo classificá-lo com um rótulo.
Definimos o modelo como uma função que mapeia as variáveis em rótulos de . Esta função é o modelo ou classificador. Com este modelo, podemos determinar o rótulo de qualquer registo ainda não observado.
Algoritmo de Aprendizagem
De modo a aprender automaticamente estas funções de mapeamento, utilizam-se algoritmos de machine learning que analisam os registos e tentam criar um modelo que satisfaz todos os registos contidos nos dados. O algoritmo procura, então, a função que minimiza o erro de classificação, ou seja, o número de registos incorretamente classificados no conjunto de dados.