Memória Virtual
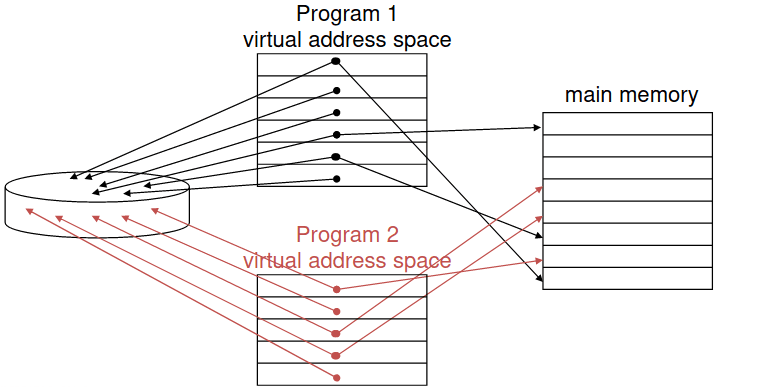
Usando a memória principal como uma "cache" para o armazenamento secundário (no disco), esta tem que ser gerida tanto pelo hardware do CPU como pelo sistema operativo (OS). Assim, cada programa é compilado para o seu próprio espaço de endereçamento, um espaço de endereçamento virtual. Nos programas que partilham a memória principal, cada um tem direito a um espaço de endereçamento físico privado que é frequentemente usado para código e dados, assim como é protegido dos outros programas. O CPU traduz o endereço virtual para um enderço físico, tendo, por isso, a VM um "bloco" que se chama página e em vez de dizermos que houve um "miss" dizemos que houve uma page fault.
Quando dois programas partilham memória física, isto significa que o espaço de endereçamento de um programa está divido em páginas (todas de um tamanho fixo) ou em segmentos (de tamanho variável). O início da localização de cada página, quer seja na memória principal ou secundária, é contido na tabela de página do programa.
Tradução do Endereço
O endereço virtual é traduzido num endereço físico através de uma combinação de hardware e software. Desta forma, cada pedido de memória precisa de, primeiro que tudo, um espaço físico. Quando há uma miss na memória vitual, isto é, quando a página não está na memória física, é o que chamamos de page fault.
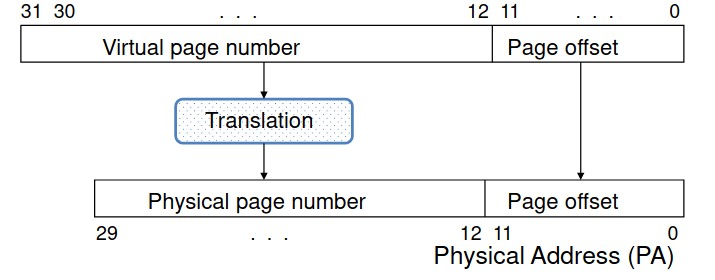
Sempre que a cache acomoda um subcojunto de posições da memória principal, a memória principal acomoda um subconjunto de posições da memória virtual. Cada bloco corresponde a uma página. A dimensão é geralmente bastante elevada de modo a aumentar a eficiência quando o disco é acedido, e também reduz a dimensão da tabela de tradução; porém, quanto maior for a página, maior é a potencial perda de memória (em média, 50% da dimensão da página); valores típicos de página são os 4 ou 8 Kbytes.
Uma página pode ser posicionada em qualquer espaço de memória visto a memória principal ter associatividade total.
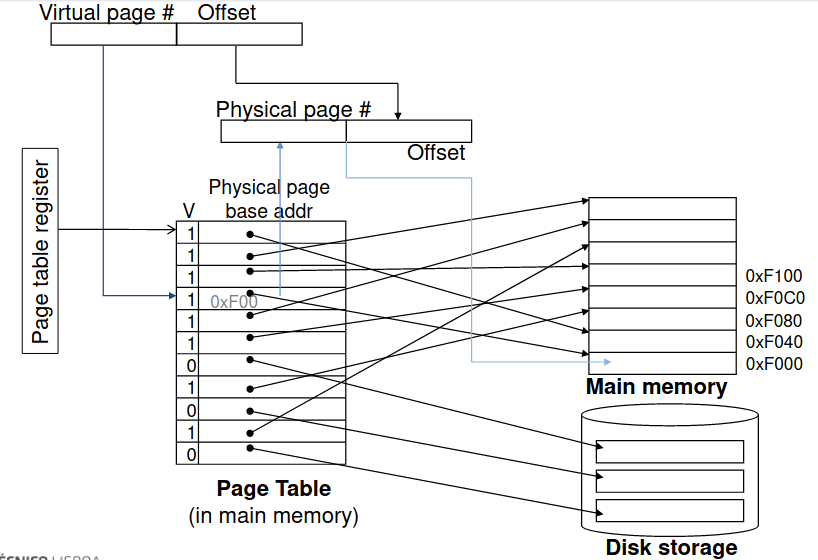
Tabelas de Páginas
As tabelas de páginas guardam o posicionamento da informação num array de entradas todas indexadas pelo número da página virtual. A tabela de páginas regista o endereço de memória física para onde aponta a página do endereço virtual além de outros bits de estado (dity, referenced, ...); caso contrário, o PTE pode referir outra localização em troca de espaço no disco.
Trocas e Escritas
Tal como já tinhamos visto em memória física, ao fazermos uma troca em memória virtual, de modo a reduzirmos o número de page faults é preferível usar o método LRU. Assim, temos que ter um reference bit na PTE que está a 1 quando temos acesso à página e é periodicamente limpo a 0 pelo OS. Se o reference bit está a zero quer dizer que já não é usado há algum tempo.
A escrita em disco demora milhões de ciclos, visto que vamos fazendo um bloco de cada vez e não localizações individuais, o que torna o write-through imprático. Por isso temos que usar o write-back sendo que o dirty bit é definido quando a página é escrita.
Tamanho das Tabelas de Página
Um problema comum na paginação de sistemas é que a dimensão de uma tabela de página não é obrigada a traduzir os endereços: apenas precisa de alocar numa região contida a memória física. Por exemplo, se temos um espaço virtual com bytes e páginas com 4 kbytes, ou seja bytes, temos uma tabela com entradas visto que , ou seja temos 1 milhão entradas!
Hierarquia das Tabelas de Página
Contudo, a questão vem: como é que podemos hierarquizar as nossas tabelas de páginas? Uma solução comum para este problema é implementar a tradução com a hierarquia da tradução das tabelas.
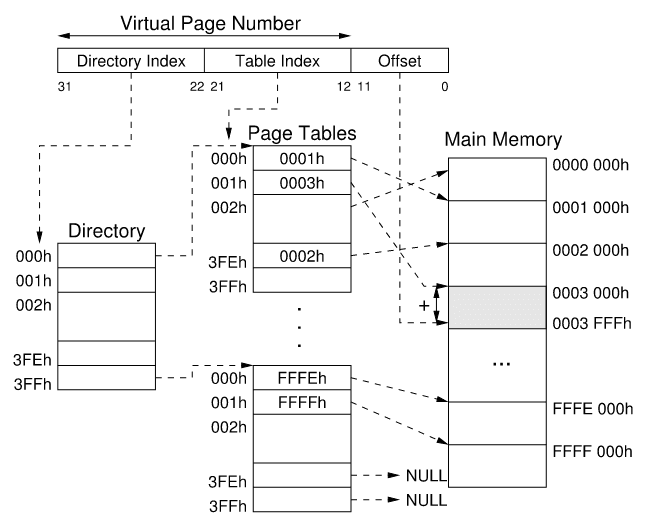
Exemplos
Para mais exemplos de cálculos com hierarquia de memória é recomendada a realização da 5ª ficha das aulas práticas ou ver a sua resolução.
Tabelas Invertidas
A tradução de endereços é baseada em hash tables. Uma qualquer função hash H(x) é aplicada ao endereço virtual de modo a encontrar uma fila particular de descriptores composta pelos pares página virtual - página física , que correspondem a endereços virtuais dando origem ao mesmo valor da função hash H(x) em termos de colisões. Assim, o endereço físico necessário pode, ou não, estar presente nessa mesma fila de descriptores.
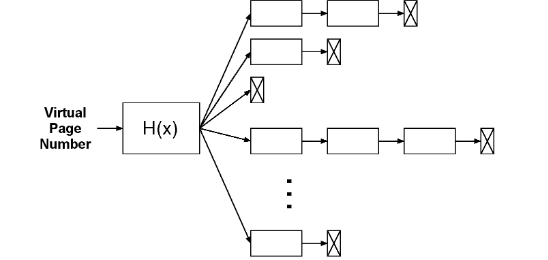
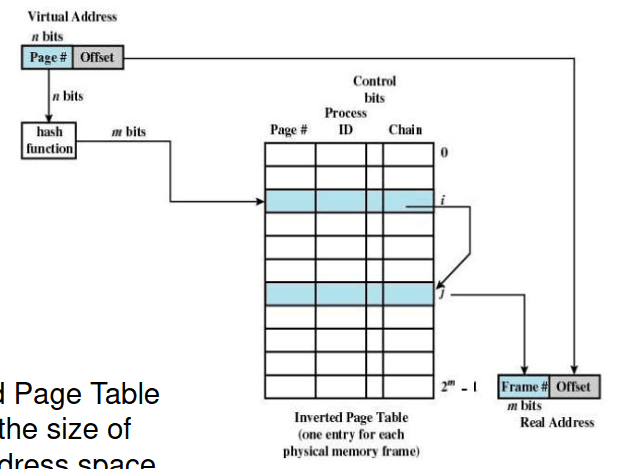
Sabemos, ainda, que o tamanho da tabela de página invertida é proporcional ao tamanho do espaço de endereçamento físico.
Assim, é necessária memória extra para aceder a tradução de VA para PA. Isto faz com que os acessos à memória sejam ainda mais caros, e a maneira de resolver o problema de hardware é através de um Translation Lookaside Buffer isto é, uma TLB, que corresponde a uma cache mais pequena que acompanha os endereços acedidos de modo a evitar ter que recorrer à tabela de página para os encontrar.
Translation Lookaside Buffer ou TLB
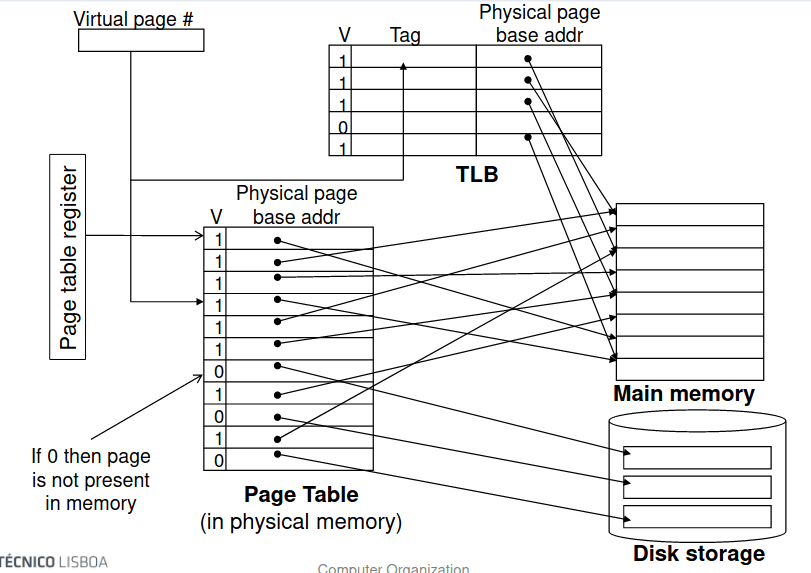
Tal como em qualquer outra cache, a TLB pode ser organizada de modo a ser totalmente associativa, ou diretamente mapeada. O tempo de acesso à TLB é extremamente menor que o tempo de acesso à cache visto que as TLBs são muito menores e são desenhadas para ser rápidas!
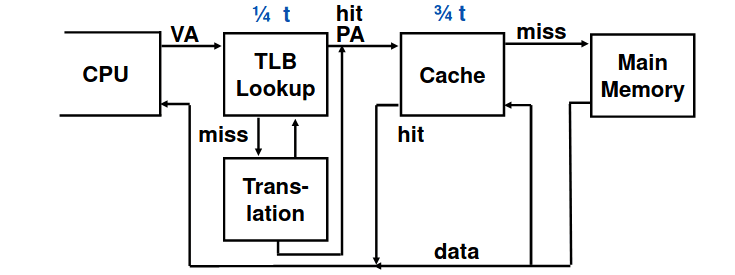
Assim, quando ocorre um TLB miss, é necessário reconhecer como miss antes que o registo do destino seja sobrescrito, dando origem a uma exceção. Assim o handler copia o PTE da memória para a TLB, reiniciando a instrução e, caso a página não esteja presente, irá ocorrer uma page fault.
No caso de uma page fault, é utilizado um endereço de memória virtual falhado para encontra o PTE, localiza a página do disco, escolhe a página que pretende repôr (caso seja dirty escreve no disco primeiro), a página é lida para memória e a tabela de página é atualizada fazendo com que o processo possa funcionar novamente, e por isso, a instrução que falha é reiniciada.
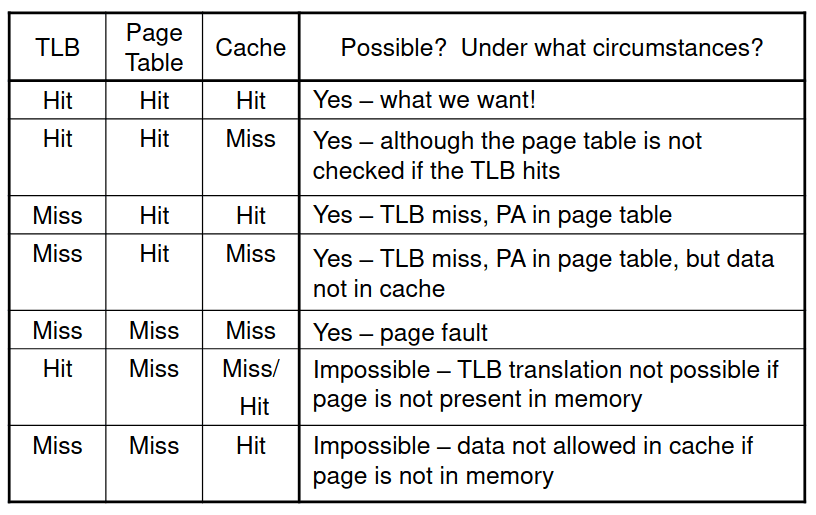
Interação entre a TLB e a Cache
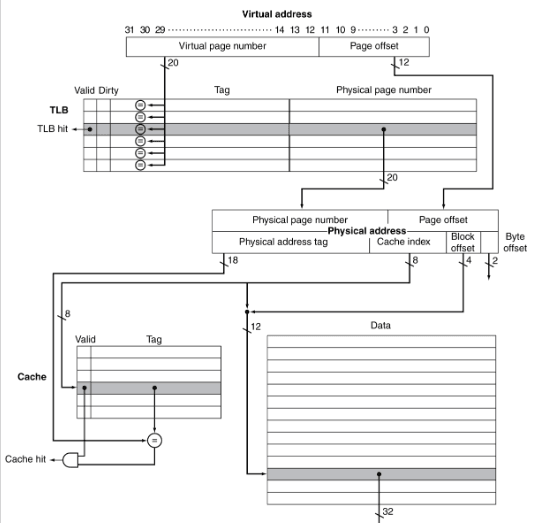
Se a tag da cache usa um endereço de memória, é necessário traduzir antes de ir procurar a cache. Uma alternativa é usar uma tag de endereço de memória virtual, contudo, tal pode ser complicado graças a aliasing, isto é, diferentes endereços virtuais para endereços físicos partilhados.
Mas, porque é que a cache não é virtualmente endereçada? Uma cache virtualmente endereçada apenas necessitaria da tradução de endereços em caso de haver cache miss. Porém, dois programas que estão a partilhar memória têm que ter dois endereços de memória virtual diferentes para o mesmo endereço físico (aliasing), desta forma, tem que haver duas cópias dos dados partilhados na cache e em duas entradas na TLB o que podem dar origem a problemas de coerência. Para isto, é necessário atualizar todas as entradas da cache com o mesmo endereço físico ou a memória torna-se inconsistente.
Redução do Tempo de Tradução
Sabendo que a interpretação de endereços virtuais pela TLB é representada da seguinte forma:
| Virtual page index | Virtual offset |
|---|
E que a interpretação dos endereços físicos pela cache é representada da seguinte forma:
| Tag | Index | Offset |
|---|
Como é que podemos paralelizar o acesso? O campo do offset do endereço virtual não participa no processo de tradução dos endereços, assim, se o offset do endereço virtual é maior ou igual ao index mais o offset, o campo do index da cache está incluido no offset do endereço virtual. Por isso, a cache pode ser lida em paralelo com o teste da TLB.
Este acesso paralelo pode originar uma sobreposição entre o acesso à cache e o acesso à TLB, visto que funciona em bits de ordem superior do VA que são usados para aceder à TLB enquanto os bits de ordem inferior são usados como index para a cache.
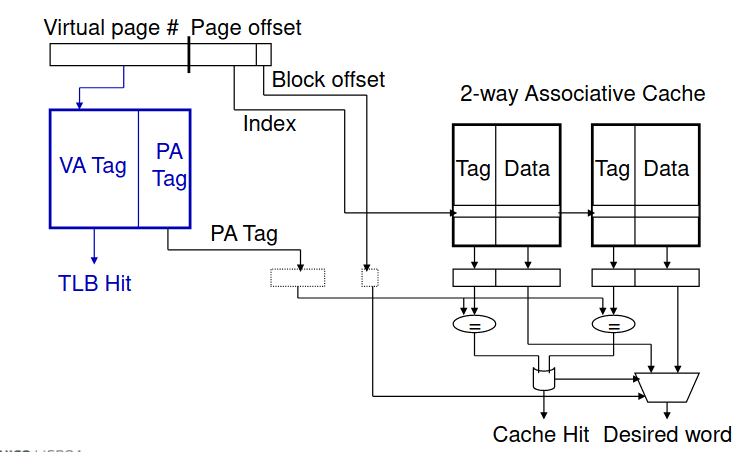
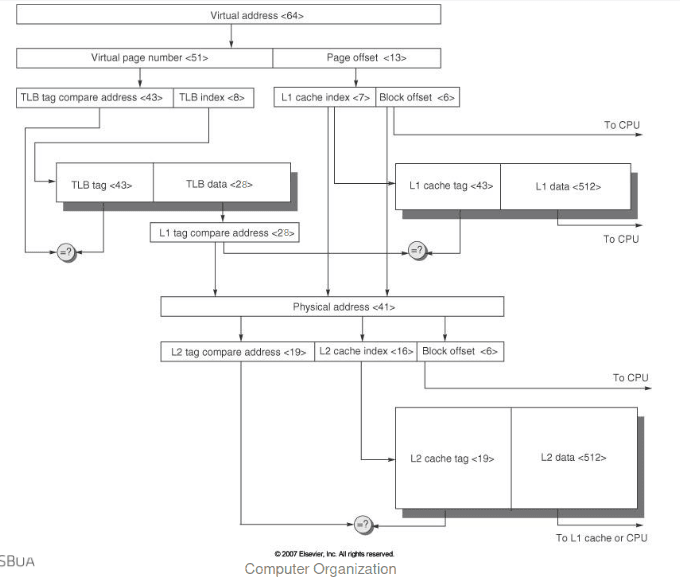
Por isso, um dos seguintes cenários pode ocorrer:
- Hit tanto na TLB como na cache: tempo de acesso parecido ao tempo de acesso à cache;
- Hit na TLB mas miss na cache: tempo de acesso parecido ao acesso à memória principal e o cache miss;
- Miss na TLB: é necessário esperar pela tradução, pela hierarquia ou pela tabela invertida, assim como não existe um ganho muito elevado no acesso à cache.
Proteção de Memória
Como é evidente, diferentes tarefas podem partilhar partes dos seus espaços de endereçamento virtual, mas é necessário proteger contra acessos errantes. Para tal, precisamos de ajuda do sistema operativo.
Existe suporte de hardware para proteção do OS, pelo que temos um modo supervisor privilegiado, isto é, o kernel mode, instruções privilegiadas, tabelas de páginas e outros estados de informação que só podem ser acedidos com o modo supervisor e uma chamada de exceção do sistema.
Hierarquia de Memória
Se tivermos a ver em termos de panorama geral, os princípios comuns aplicam-se a todos os níveis da hierarquia de memória, baseado nas noções de caching. Assim, a cada nível de hierarquia temos:
-
Block placement: determinado pela associatividade; é mapeado diretamente (só tem uma escolha de posicionamento), tem uma associatividade com um set de n sentidos (tem n escolhas dentro de um set), ou é totalmente associativo (pode ir para qualquer localização). Quanto maior for a associatividade, menor é o miss rate, aumenta a complexidade, custo e tempo de acesso.
-
Finding a block: tem caches hardware que reduzem a comparação de modo a reduzir o custo assim como memória virtual numa tabela de procura de associatividade total fazível e tem um miss rate reduzido.
-
Replacement on a miss: escolha de entrada para substituir em caso de miss que pode ser através da política LRU ou aleatório; em termos de memória virtual o LRU tem uma aproximação com o suporte de hardware.
-
Write Policy: como já tínhamos visto anteriormente, podemos ter write-throughs que atualizam tanto os níveis superiores como inferiores e simplificam a troca mas precisam de um buffer de escrita; ou write-backs que apenas atualizam os níveis superior e só atualizam os inferiores quando o bloco é resposto, ou seja, é necessário manter mais estado. Assim, em termos de memória virtual, só o write-back é fazível, visto que existe uma latência de escrita no disco.