Camada de Transporte
- A Camada de Transporte
- Multiplexing
- UDP - User Datagram Protocol
- RDT - Reliable Data Transfer
- TCP - Transmission Control Protocol
A Camada de Transporte
O objetivo desta camada é providenciar comunicação entre processos a correr em hosts diferentes, ou seja, fazer o transporte de dados em canais de comunicação.
O host que envia mensagens, parte-as em segmentos.
O que os recebe, remonta os segmentos da mensagem.

Multiplexing
De forma a um servidor conseguir multiplexar/encaminhar segmentos para as devidas sockets (pois estão lá os serviços/aplicações que estão à espera dos pacotes), este olha para o porto de destino e para o IP de origem de cada segmento.
UDP - User Datagram Protocol
É um protocolo da camada de transporte simples e com implementação fácil. Tem vantagens e desvantagens:
Vantagens
- É simples;
- Tem menos delay que outros protocolos mais simples;
- Tem o cabeçalho do segmento mais pequeno;
- Não há controlo de congestionamento, ou seja, pode enviar os dados muito mais rápido.
Desvantagens
- Os segmentos podem-se perder;
- A entrega pode ser feita fora de ordem;
- Não é feita uma conexão entre o emissor e o recetor.
Dado isto, este protocolo é normalmente usado em aplicações que toleram a perda de alguns pacotes e que querem que a informação apareça o mais rápido possível (e.g. transmissões de televisão).
Este protocolo é usado pelos protocolos DNS, SNMP e HTTP/3.
No caso do HTTP/3, é aplicado um wrapper ao UDP, que inclui lógica de recuperação, conexão e
entrega em ordem dos pacotes.
De qualquer forma, é necessário algum mecanismo básico de fiabilidade.
Checksum
Este campo dos segmentos serve para detetar erros num dado segmento transmitido.
Quando o segmento é enviado, o emissor calcula e guarda a soma dos dois endereços IP enviados
(considerados números para ser possível fazer a soma) no campo Checksum.
Quando o segmento é recebido, o recetor faz a mesma soma e verifica-se se o resultado é igual ao
valor que está no campo Checksum.
Se tiver existido alguma corrupção, ou seja, pelo menos algum bit que tenha sido mal transmitido, a
soma dará um valor diferente e então o erro será detetado.
Se for esse o caso, o pacote é apenas ignorado/dropped (no caso do TCP, o segmento seria
pedido novamente ao emissor).
Contudo, este sistema continua a não ser muito confiável - podem existir várias combinações de erros que gerem a mesma soma e um erro pode também estar no checksum.
Uma melhoria que se pode fazer é considerar mais valores para o cálculo da soma do checksum, de forma a aumentar a entropia do erro - pode-se, por exemplo, também considerar valores dos cabeçalhos de outras camadas.
RDT - Reliable Data Transfer
Depois do verificado com o UDP, o ideal seria existir um canal de comunicação confiável, fazendo com que as aplicações não se tenham que preocupar com a correta chegada a informação ao destinatário e vice-versa.
Como nem todos os canais de comunicação são fiáveis, a solução foi criar um conjunto de regras que permitem a comunicação fiável sobre um canal não fiável. Exemplos destas regras são:
- Quando um pacote é enviado, o recetor tem que confirmar a sua receção;
- Se a confirmação não for recebida, reenvia-se o pacote;
- ...
Novas medidas foram aparecendo ao longo do tempo e estas constituem o protocolo RDT (conjunto de regras que permitem estabelecer uma ligação fiável sobre um canal não fiável).
RDT 1.0
Nesta versão inicial, o protocolo assume que o canal é fiável.
É o ponto de partida para as versões seguintes.
RDT 2.0
Agora considera-se que o canal pode trocar bits num segmento.
Para os identificar, usa-se o checksum, já apresentado no protocolo UDP.
Para os resolver,
- o recetor avisa o emissor que o pacote foi todo ele bem recebido, enviando um pacote ACK, ou que o pacote tinha erros, enviando um pacote NAK;
- no caso do pacote não ter sido bem recebido, o emissor reenvia o pacote, após ter recebido o NAK.
Para implementar isso, usa-se a lógica Stop and Wait - o emissor envia um pacote e fica à espera da resposta do recetor.
RDT 2.1
A versão 2.0 tem um problema crucial.
Considere a seguinte situação
- O host A quer enviar a mensagem "Hoje vai chover", separada em "Hoje", "vai", "chover", para o host B.
- O host A envia "Hoje";
- O host B recebe "Hoje" e envia um pacote ACK a confirmar a receção;
- O host A recebe o pacote ACK mas vem corrompido. Sem ter a certeza da resposta, reenvia "Hoje";
- O host B recebe novamente "Hoje": Serão mais dados ou uma repetição da mesma mensagem?
Para colmatar isso, a versão de RDT 2.1 inclui um número de sequência de forma a que o cliente possa confirmar se um segmento é repetido ou se é a continuação de uma mensagem.
RDT 3.0
Contempla uma nova assunção: E se os pacotes nunca chegarem?
Esta versão implementa um Timeout, ou seja, o emissor espera uma quantidade de tempo pela resposta
do envio de um pacote (ou seja, por um ACK).
Se, passado esse tempo, nenhum ACK for recebido, o emissor reenvia a mensagem.
Se o pacote estava apenas com um atraso grande, a retransmissão será então duplicada mas, graças ao RDT 2.1, isso não é um problema devido ao uso de números de sequência.
Seguem-se exemplos deste protocolo:




Sliding Window
O mecanismo Stop-And-Wait implica que esperemos pela confirmação de um dado segmento para enviar o seguinte.
Isto implica que, do tempo total de envio, apenas uma pequena parte seja efetivamente usada para envio,
sendo o restante tempo usado para esperar.
Olhando para o esquema seguinte,

Pode-se deduzir que a eficiência de um envio, ou seja, a fração do tempo em que o emissor está realmente a emitir, é dada por (Do tempo total de envio de um pacote e da espera da resposta, , só existe efetivamente transmissão durante ).
Isto faz com que este sistema seja bastante ineficiente.
Uma solução para este problema é, ao invés de enviar 1 pacote e esperar pela sua resposta,
ter um número máximo () de pacotes pendentes de resposta (ou seja, permito ter até pacotes pendentes).
A este esquema chama-se Sliding Window - "Janela" de tempo onde se podem enviar pacotes.
Depois dessa janela acabar, ou seja, quando se chegar ao limite de pacotes pendentes, espera-se
pela receção de pelo menos um pacote para poder enviar mais.
Por exemplo, se :
")
O ideal seria dimensionar o envio de tal forma que não exista tempo perdido:

Contudo, ainda podem existir vários tipos de perdas, como apresentado no RDT 3.0.
Para resolver esses problemas, existem "sub-protocolos" do Sliding Window:
Go-Back-N
Este protocolo pode ser visualizado usando esta ferramenta online.
Neste protocolo, o emissor vai reenviando todos os pacotes a partir do primeiro que falhou no envio. Para se entender melhor, considere-se o seguinte exemplo, com :
-
São emitidos os pacotes:
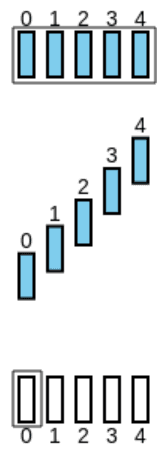
-
Contudo, o 3º pacote é perdido:
-
O recetor faz ACK de todos os pacotes recebidos até à primeira falha:
-
O emissor recebe-os, mas só considera como recebidos os pacotes até à primeira falha:

-
O emissor envia os pacotes a partir do primeiro que falhou, até ao limite de :
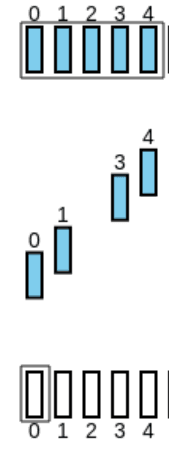
Contudo, se o pacote perdido for um ACK, este algoritmo tem isso em conta:
-
São emitidos os pacotes:
-
O recetor recebe-os e faz ACK de todos:
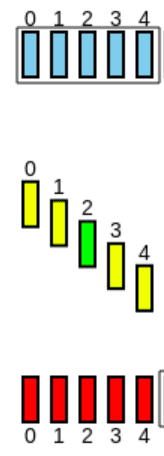
-
Contudo, o 3º ACK é perdido:
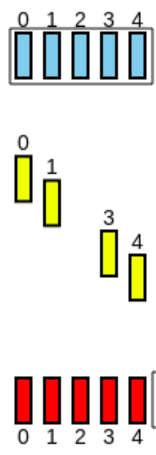
-
Porém, o 4º ACK leva a informação que todos os pacotes até ele (1º, 2º e 3º) foram recebidos, por isso, o emissor sabe que foi tudo recebido:

Sejam,
- o tamanho da janela;
- a quantidade de números usados para numerar os pacotes (ambos o emissor e o recetor têm que manter a mesma numeração de pacotes, de forma a saberem quais já foram enviados e quais são necessários receber).
Ambos têm que respeitar a seguinte condição:
Selective Repeat
Este protocolo também pode ser visualizado usando esta ferramenta online.
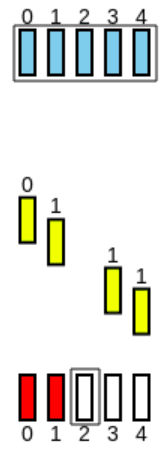
Neste protocolo, ambos o emissor e o recetor têm uma Sliding Window e estes apenas a avançam quando o pacote mais antigo for ACKnowledged. Para se entender melhor, considere-se o seguinte exemplo, com :
-
São emitidos os pacotes:
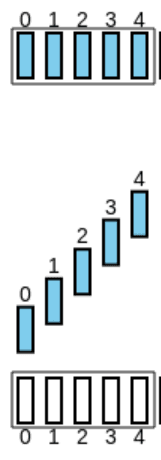
-
Contudo, o 2º pacote é perdido:
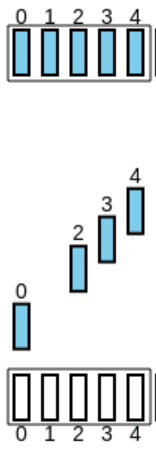
-
O emissor envia os ACKs de cada pacote, mexendo a sua Window:
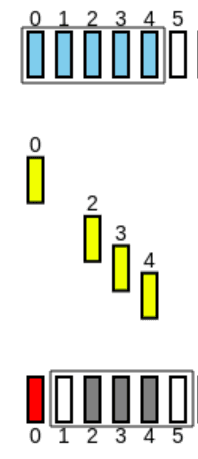
-
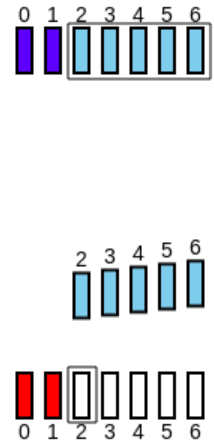
O emissor regista os pacotes recebidos e mexe a sua Window até ao primeiro pacote não recebido, ficando a par com o recetor:

-
O emissor reenvia os pacotes perdidos (neste caso, o 2º pacote), bem como todos os restantes pacotes que fazem parte da Window e que não foram enviados:
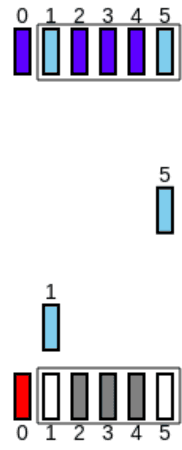
Neste caso, a seguinte condição tem que ser respeitada:
TCP - Transmission Control Protocol
Criado com a ideologia do RDT em mente, veio o protocolo TCP - Transmission Control Protocol. Este protocolo tem as seguintes características:
- Point-to-Point - Apenas um emissor e um recetor;
- Sliding Window - Implementa a noção de Sliding Window, apresentada anteriormente;
- Dados Full Duplex - Na mesma conexão, é permitido enviar dados nos dois sentidos;
- Orientado a conexão - Implementa uma conexão, ou seja, dois hosts conhecem-se (vs. o UDP, em que o recetor recebe informação de vários emissores sem estabelecer uma conexão).
- Controlo de Flow - O emissor consegue controlar a quantidade de dados enviados, caso o cliente não consiga processar tudo.
Estrutura de um segmento TCP
De forma a conseguir implementar estas medidas, o TCP altera a estrutura do segmento apresentada anteriormente:

Onde os campos que se destacam são,
- Número de sequência - conta o número de bytes enviados, desde o inicio da conexão. É igual ao n-ésimo byte já enviado pelo dado host incrementado por uma unidade (correspondente ao primeiro byte enviado deste segmento);
- Número de ACK - número de sequência do byte seguinte que se espera receber. Este indica que foram recebidos os dados acumulados até este ACK (ou seja, todos os ACKs anteriores chegaram) e que se pretende receber os dados associados a este ACK.
- Bit A - diz se o segmento é um ACK;
- len cab - tamanho do cabeçalho;
- Janela de Receção - número de bytes que recetor consegue receber;
- Bit R, S, F - diz se o segmento é um RST, SYN ou FIN;
- Bit E e Bit C - notificação de congestão na rede.
Three Way Handshake - Estabelecer uma conexão
Antes de serem transmitidos dados, o emissor e o recetor criam uma conexão, através do Three Way Handshake:
- O cliente envia um segmento SYN para o servidor, indicando o número de sequência inicial;
- O servidor responde com um SYN ACK, indicando o seu número de sequência inicial. Aqui, o servidor aloca buffers.
- O cliente responde com um ACK, podendo já enviar dados com este segmento.
Para terminar a conexão,
- O cliente envia um segmento FIN para o servidor;
- O servidor responde com um ACK e começa a fechar a conexão;
- O servidor, depois de fechar completamente a conexão, responde com um FIN;
- O cliente responde ao FIN recebido com um ACK. Mesmo depois de receber o FIN, como os pacotes podem não chegar por ordem, o socket não é fechado imediatamente pois ainda podem chegar pacotes.
- o servidor recebe o ACK, que confirma que a conexão foi totalmente (dos dois lados) fechada.
Comparar números de segmento
Considere o seguinte esquema, onde existe um servidor que faz "echo" do que os clientes enviam. O esquema mostra uma conexão já anteriormente inicializada e alguns dados trocados,

- O cliente envia a letra 'A'. O segmento contém o número de sequência 40 e o ACK 80.
- O servidor envia o segmento com o número de sequência 80 (visto que o ACK recebido representa
que todos os segmentos até ao 80 foram recebidos e que o número de sequência que se pretende
receber é o 80).
O servidor envia o ACK 41, avisando que recebeu tudo até ao número de sequência 40 e que quer receber o 41.
O servidor envia a letra 'A', pois está a fazer echo das mensagens recebidas. - O cliente responde com o número de sequência e o ACK (não são enviados dados pois o
objetivo deste segmento é confirmar a receção do segmento anterior).
O cliente envia o número de segmento 41, pois é número do ACK que recebeu do servidor;
O cliente envia o ACK 81, avisando que recebeu tudo até ao segmento 80 e quer o segmento 81.
warning
Em TCP, os "números de segmento" correspondem ao índice do byte na mensagem. Por exemplo, a mensagem "AA" iria aumentar o número de segmento por 2, dado que contém 2 bytes.
Timeout
Cada segmento tem que ter um dado tempo para, caso esse tempo seja passado e não seja obtida resposta, podermos considerar o segmento como perdido. A esse tempo chama-se timeout.
O tempo de timeout tem que ser maior do que o RTT e, portanto, é necessário saber o tempo de RTT.
É possível estimar este valor fazendo a diferença entre o tempo de emissão de um segmento e da
receção do respetivo ACK. A este tempo chama-se (visto ser uma amostra do tempo
possível).
Contudo, uma amostra do tempo não é suficiente, visto que a rede, nesse instante, podia estar instável e
não representar a realidade.
Então, alternativamente, calcula-se o , que é uma média de vários s.
Alternativamente a esses tempos, pode-se ainda calcular o (tipicamente, ). A esta fórmula chama-se EWMA (Exponential Weighted Moving Average), e com ela, a influência das amostras anteriores diminui exponencialmente.
Envio de um segmento
O flow de envio de dados é o seguinte:
- criar um segmento;
- definir o número de sequência como o primeiro byte de dados deste segmento. Por exemplo,
- se for o primeiro segmento a ser enviado, o número de sequência será 1;
- se já tiverem sido enviados 1000 bytes, o número de sequência será 1001.
- Enviar o segmento e começar um timer.
- Se o timer passar e não tiver sido recebida uma confirmação, reenvia-se o segmento que causou o timeout. O tempo de espera é dobrado para evitar timeouts prematuros de segmentos seguintes.
- É recebido um ACK, confirmando todos os segmentos enviados até ao valor do ACK.
Se os segmentos ainda não estavam confirmados, são agora confirmados. Recomeça o timer, se ainda existirem outros segmentos por confirmar.
Apesar de existir o timeout, o período de espera é relativamente longo. Uma solução para isso é fazer uma retransmissão rápida - assume-se que se existirem 3 ACKs duplicados, deve-se retransmitir imediatamente.
Note-se que, se algum segmento não tiver chegado, o servidor irá sempre responder com ACKs até esse segmento, mesmo que entretanto cheguem segmentos posteriores, pois o ACK, em TCP, representa que todos os segmentos até ao seu número foram recebidos com sucesso. Por exemplo,
- O cliente envia um segmento com número = 1.
- O servidor responde com ACK = 2 (recebeu tudo até 2 e quer receber o 2).
- O cliente envia um segmento com número = 2.
- O servidor responde com ACK = 3.
- O cliente envia um segmento com número = 3. O Pacote perde-se.
- O cliente envia um segmento com número = 4.
- O servidor responde com ACK = 3 (Apesar de ter recebido o segmento 4, o servidor só pode responder com 3 pois o ACK é acumulativo, ou seja, só recebeu tudo até ao 2).
- O cliente envia um segmento com número = 5.
- O servidor responde com ACK = 3.
- O cliente envia um segmento com número = 6.
- O servidor responde com ACK = 3.
- O cliente recebe 3 ACKs repetidos e então retransmite o segmento 3.
- O servidor responde com ACK = 7 (Recebeu todos os pacotes até ao 6 e pode receber o 7).
Controlo do fluxo
Um dos objetivos do TCP é assegurar que a transmissão não é feita rápido de mais, ou seja, que o recetor consegue processar todos os dados de um segmento antes de receber o seguinte.
O recetor tem um buffer de receção - buffer para onde vão os dados que vão sendo recebidos
através de TCP.
Uma forma de controlar o fluxo é o recetor avisar o espaço livre que tem no buffer a cada ACK
enviado para o emissor através do cabeçalho Janela de Receção.
Desta forma, é garantido que não existirá overflow de dados.
Controlo de congestão
Outro problema que o TCP consegue antever é a congestão na rede.
Poderá haver congestão na rede se não existirem sincronizações de tráfego, ou seja, se as múltiplas
transmissões não souberem que as outras existem e portanto enviarem todas dados a uma velocidade maior
que o suposto.
Para além disso, se existir tráfego em demasia e passar por um router, este pode não ter capacidade
suficiente para segurar a informação toda e então descarta pacotes.
Isso implica que terá que ser feita uma nova transmissão e, consequentemente, causar ainda mais
tráfego na rede.
Essa situação tem a agravante de, se existirem cadeias de routers, apesar do tráfego conseguir
passar um dos routers, poder ser descartado mais tarde, causando ainda mais latência.
Para conseguir controlar a congestão, existem duas soluções para o problema: Controlo através da rede e Controlo end-end:
Controlo através da rede
Nesta solução, os routers dão feedback direto aos hosts, informado quão congestionada a rede está.
O feedback é passado pelos vários routers até chegar ao host final e, com esse feedback, os
emissores podem reduzir o seu ritmo.
Esse feedback é passado nos bits E e C do header de um segmento de TCP.
Controlo end-end - AIMD
Nesta solução, não existe um feedback explicito da rede. Em vez disso, a congestão é inferida através do delay e das perdas de pacotes observadas.
No caso do TCP, usa-se um algoritmo de AIMD (Additive Increase/Multiplicative Decrease), onde
os emissores começam com um ritmo base e vão aumentado esse ritmo aos poucos.
Se, à medida que o ritmo vai aumentando, existir uma perda (o que significa que o canal está a ficar
mais congestionado), então a velocidade é reduzida drasticamente.
Detalhadamente, os aumentos são de dois tipos, baseados num threshold:
- Se a velocidade estiver abaixo do threshold, os aumentos são exponenciais - duplicando a velocidade a cada envio;
- Se, com um aumento, a velocidade passar desse threshold, o aumento passa a ser constante e de 1 segmento extra por envio.
Em relação aos decréscimos:
- São em metade de velocidade, caso seja detetado o mesmo ACK três vezes;
- São para o mínimo possível - 1 MSS (Maximum Segment Size), caso seja detetada uma perda.
O valor do threshold é um valor fixo quando a transmissão começa, mas, sempre que existe um decréscimo, o seu valor muda para metade da velocidade atual (antes desta ser reduzida).
Resumidamente,
- Quando uma conexão começa, a velocidade é a mais lenta possível - 1 MSS. A isto chama-se slow start.
- Contudo, como a velocidade é muito inferior ao threshold, esta irá crescer exponencialmente até o alcançar. Depois disso, entra na fase de congestion-avoidance, onde o crescimento é linear.
- Se o mesmo ACK for repetido três vezes, o threshold é passado para metade da velocidade atual e a velocidade para metade;
- Se existir um timeout, o threshold é passado para metade da velocidade atual e a velocidade para 1 MSS.
Olhando para um gráfico temporal que representa a velocidade de envio, este terá um aspeto de uma serra:

Estado de Fast Recovery
Se forem detetados três ACKs duplicados pode ser usado o estado de Fast Recovery, onde se tenta acelerar a recuperação enviando apenas os segmentos perdidos antes de se transitar novamente (ou pela primeira vez) para o estado de congestion-avoidance.
Neste caso, a congestion window é incrementada em 1 MSS por cada ACK duplicado recebido que causou a entrada neste estado, este aumento da congestion window com pacotes duplicados não acontece nos outros estados e é a principal diferença do Fast Recovery.
Finalmente, depois do ACK que confirma a receção do segmento perdido, move-se para a fase de congestion-avoidance.
Nota: É uma boa ideia olhar para a State Machine dos slides pois é muito mais simples olhar para as transições e estados que existem ao invés de estar a tentar percebê-lo por escrito.
Variações
Existem variações de implementação do AIMD. Por exemplo, em Linux, é usado TCP CUBIC onde se
assume que, quando é detetada uma congestão, esta não vai ser muito alterada.
Desta forma, podemo-nos aproximar mais rapidamente da velocidade que provocou a congestão anterior
(visto que se assume que esta se manteve) e quanto mais perto estivermos, mais lentamente nos aproximamos.
Comparando as duas implementações num só gráfico, teriam este aspeto:

Fairness de TCP
Se existirem várias conexões a utilizar o mesmo meio, o TCP tenta partilhá-lo, de forma a tornar a ligação equitativa para todos.
Com os mecanismos apresentados anteriormente, ao fim de certo tempo, a partilha tende a aproximar-se do mais justo, pois as velocidades tendem a equilibrar-se.
Contudo, um browser pode, por exemplo, gerar várias conexões por cada tab aberta, o que faz com que estas (que representam uma ligação maior) fiquem com uma grande parte do canal.
Não existe forma de controlar isso no TCP.
QUIC - Quick UDP Internet Connections
Como mencionado anteriormente na camada de Aplicação, recentemente foi criado o protocolo QUIC (Quick UDP Internet Connections), inventado pela Google.
O QUIC, como o nome indica, usa UDP. No entanto, implementa muitas das funcionalidades de TCP e ainda outras adicionais como, por exemplo, segurança (autenticação, encriptação) e estabelecimento de conexões (controlo de congestionamento diferente, fiabilidade).