APIs de Comunicação
Representação externa de dados e marshalling
A informação armazenada em programas é representada com diversas estruturas de dados, enquanto que a informação transmitida em mensagens consiste numa sequência de bytes. Independentemente da forma de comunicação utilizada, as estruturas de dados devem ser flattened (convertidas numa sequência de bytes) antes da transmissão e reconstruídas na chegada.
Visto que nem todos os computadores armazenam os valores primitivos da mesma forma, um dos seguintes métodos pode ser utilizado para permitir que dois computadores troquem dados binários:
- Os valores são convertidos para um formato externo acordado antes da transmissão e convertidos para o formato local ao serem recebidos
- Os valores são transmitidos no formato do remetente, juntamente com uma indicação do formato utilizado, e o destinatário converte os valores se necessário
Protocolos request-reply
Esta forma de comunicação foi concebida para suportar as roles e trocas de mensagens das interações típicas cliente-servidor. Normalmente, a comunicação request-reply é síncrona porque o processo cliente bloqueia até receber resposta do servidor. A comunicação assíncrona pode ser útil em situações em que os clientes podem receber as respostas mais tarde.
Embora muitas implementações atuais usem TCP, um protocolo baseado em UDP evita overheads desnecessários, em particular:
- Os acknowledgements são redundantes, uma vez que os pedidos são seguidos por respostas
- Estabelecer uma conexão envolve dois pares extra de mensagens para além do par necessário (pedido e resposta)
- O controlo de fluxo é redundante para a maioria das invocações, visto que usam argumentos e resultados pequenos
Nota
Muitas vezes é difícil decidir o tamanho apropriado para o buffer no qual vamos receber os datagramas (isto aplica-se tanto do lado do cliente como do servidor). O tamanho limitado dos datagramas pode não ser adequado para sistemas RMI ou RPC, uma vez que os argumentos e resultados dos procedures podem ter um tamanho arbitrário.
Exemplo de aplicação UDP
Vamos analisar o comportamento de uma aplicação cliente-servidor que utiliza UDP para a troca de mensagens. Ao utilizar UDP, sabemos que as mensagens podem:
- Perder-se
- Chegar fora de ordem
- Chegar repetidas
Imaginemos um caso em que o cliente não recebe resposta ao seu pedido. Tem agora 2 opções: ou retorna erro ou repete o envio.
Se chegar uma resposta depois do reenvio, pode ter acontecido 1 de 3 cenários:
- O pedido original não chegou ao servidor (operação executada apenas 1 vez)
- A resposta ao pedido original perdeu-se (operação executada 2 vezes)
- O servidor recebeu o pedido original e começou a processá-lo, mas crashou, podendo a operação ter sido realizada ou não caso não seja atómica (operação executada 1 ou 2 vezes)
O facto de a operação ser repetida, além de desperdiçar tempo, pode ter efeitos inesperados caso esta não seja idempotente (operação que produz o mesmo estado e devolve a mesma resposta independentemente do número de vezes que for executada).
Como é que o servidor pode evitar isto? Tem que ser capaz de verificar se o id do pedido já foi recebido anteriormente:
- Se for a primeira vez: executa a operação normalmente
- Se for repetido: deve ter guardado o histórico de respostas a pedidos executados e retornar a resposta correspondente (isto implica o armazenamento de ids e suas respostas)
Conseguimos assim perceber que programar sistemas distribuídos através de sockets é bastante complexo e vulnerável a falhas, pelo que iremos utilizar mais um nível de abstração, o RPC.
RPC
O RPC (Remote Procedure Call) permite que um cliente execute funções (procedures) remotamente num servidor mas de forma aparentemente local. O facto da execução ser remota levanta dois problemas principais:
- A rede entre o cliente e o servidor não é reliable, tendo tendência a perder e reordenar mensagens
- Os computadores onde ambos os processos correm podem ter arquiteturas muito diferentes
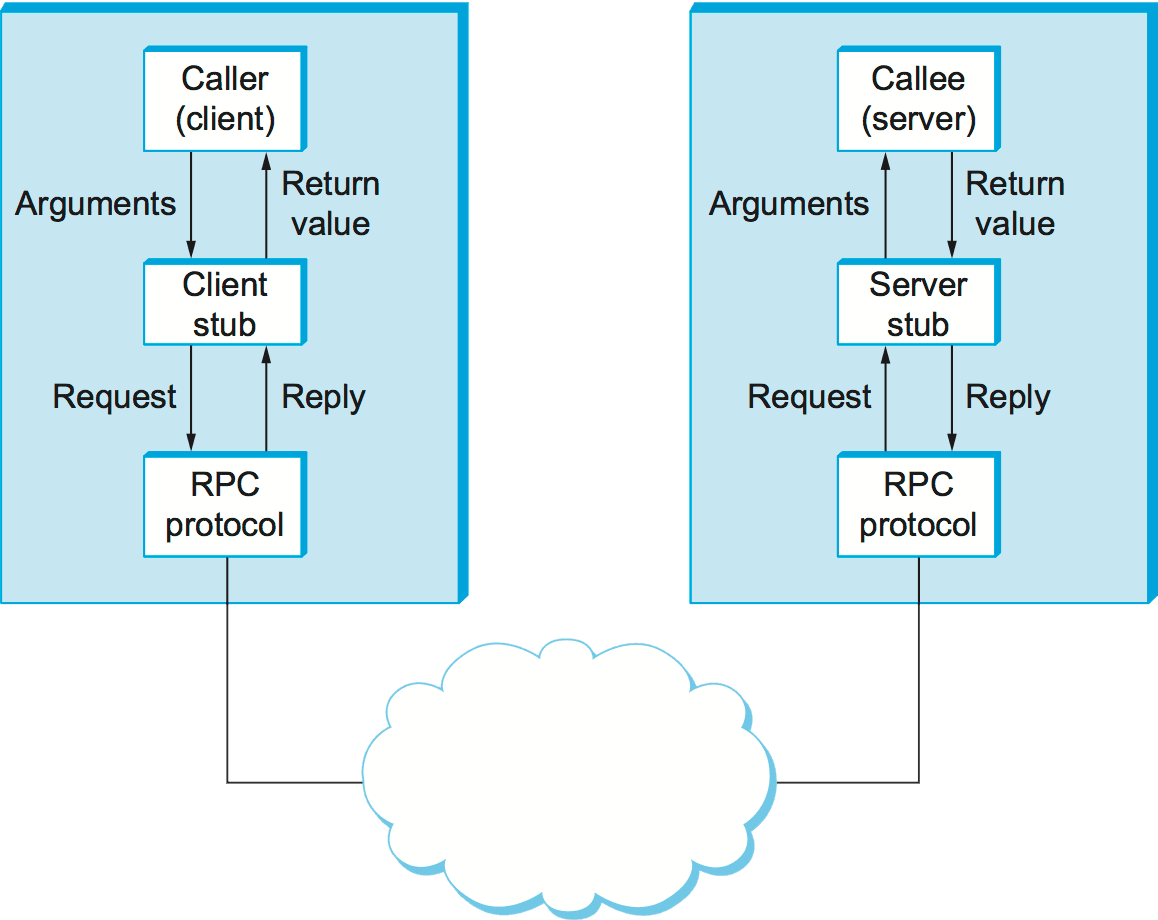
Programação típica com RPC:

As Interface definition languages (IDLs) foram concebidas para permitir que os procedimentos sejam invocados noutras linguagens de programação. Uma IDL fornece uma notação para definir interfaces e parâmetros de operações (input e output).
Este processo segue um mecânismo de request reply:
- O cliente passa os argumentos do procedure para o local stub, que os transforma num request (mantendo assim a ilusão de que se está a chamar um procedure local)
- O stub invoca o protocolo RPC para enviar este request para o servidor
- O servidor recebe o request, que é traduzido pelo seu stub de forma a obter os argumentos (utilizando o mesmo protocolo)
- Executa localmente o procedure
- Devolve uma resposta ao cliente de acordo com o protocolo
- O stub do cliente traduz a resposta e obtém assim o valor, que devolve ao programa que chamou o procedure
Existem várias semânticas de invocação (e mecanismos associados):
- Maybe : Não há garantias de que o procedure é executado
- mecanismos: RPC timeout
- At-least-once : O procedure é executado pelo menos 1 vez
- mecanismos: RPC timeout + Resend
- At-most-once : O procedure é executado no máximo 1 vez
- mecanismos: RPC timeout + Resend + Message id + Response history
- Exactly-once : O procedure é executado exatamente 1 vez
- mecanismos: RPC timeout + Resend + Message id + Response history + Transaction rollback
Transparência
Os criadores do RPC queriam tornar as chamadas de procedimento remoto idênticas às chamadas locais (sem distinção na sintaxe). No entanto, as chamadas de procedimento remoto são mais suscetíveis a falhas, devido à presença de uma rede, outro computador e outro processo. Isto exige transparência para que os clientes sejam capazes de recuperar caso haja falhas.
A implementação que iremos utilizar na cadeira é o gRPC.
gRPC
Tem como base HTTP/2 e por sua vez TLS e TCP. É um mecanismo focado em serviços cloud (e não no paradigma cliente/servidor) baseado no RPC utilizado internamente pela Google.
- Utiliza uma IDL (Interface Definition Language) para especificar os tipos
dos dados e quais as operações disponíveis.
- Um exemplo de IDL é o protobuf utilizado pela Google, que fornece o seu compilador protoc para gerar código (por ex. Java)
- Fornece ferramentas de geração de código a partir da IDL (conversão de dados + invocação remota)
- As chamadas remotas podem ser síncronas ou assíncronas
Uma chamada remota gRPC:
- É constituída por:
- Um nome de serviço e de método, fornecido pelo cliente
- Meta-dados opcionais (key-value pairs)
- Um ou mais pedidos
- Termina quando o servidor responde com:
- Zero ou mais mensagens de resposta
- Meta-dados opcionais
- Um trailer (indica se a chamada foi bem sucedida ou se ocorreu um erro)
Dado que estamos a utilizar a rede, podem acontecer falhas (o que deve ser tido em conta ao escrever os clientes) e portanto podem ser devolvidas respostas com códigos de resultado em vez do tipo definido na IDL. Alguns exemplos:
- 0 - OK
- 5 - not found
- 13 - internal
De forma a saber como contactar o servidor, o gRPC utiliza por omissão DNS como servidor de nomes.
Referências
- Coulouris et al - Distributed Systems: Concepts and Design (5th Edition)
- Secções 4.2 e 5.1-5.3
- Larry Peterson and Bruce Davie -
Computer Networks: A Systems Approach
© Elsevier 2012 (License CC BY 4.0)
- Secção 5.3
- Imagem que ilustra funcionamento do RPC
- Departamento de Engenharia Informática - Slides de Sistemas Distribuídos (2022/2023)
- 2b - gRPC
- Departamento de Engenharia Informática - Slides de Sistemas Distribuídos (2023/2024)
- SlidesTagus-Aula01b