Gestão de Processos
Gestor de Processos
Sabemos por experiência própria que podemos ter dois ou mais processos a executar no nosso computador. Mas como? O nosso processador apenas consegue executar uma instrução de cada vez. Bem na realidade é isso que acontece: apenas é executada uma instrução de cada vez, mas o Gestor de Processos vai alternando entre os vários processos de forma a dar a ilusão que estão a ser executados concorrentemente.
O Gestor de Processos é uma entidade do núcleo (kernel) que, além de efetuar a transição entre vários processos e tarefas (threads), é também responsável pelo tratamento de interrupções, otimização da gestão de recursos dos processos (escalonamento, scheduling) e da implementação das chamadas de sistemas relacionadas com processos e sincronização entre os mesmos (como por exemplo a alteração da prioridade de um processos; veremos mais à frente o que isto significa).
Processos e Tarefas
Para percebermos como é que o sistema operativo vai transitar entre vários processos, temos de aprender como é que estes são representados no núcleo (kernel).
Quando trocamos o processo em execução, temos de guardar o contexto do processo que estava em execução e substituí-lo pelo contexto do novo processo. Um processo tem contexto tanto no hardware como no software.
No hardware, tal como já vimos em IAC, existem registos do processador. Os valores desses registos (acumulador, genéricos, program counter, stack pointer, flags de estado, etc) fazem parte do contexto do processo, e têm de ser guardados/restaurados quando se troca o processo em execução. Além disso, é preciso também guardar/restaurar os registos da unidade de gestão de memória (UGM).
Por outro lado, no software, são guardados metadados sobre o processo em execução. Informações como a identificação do processo (PID, utilizador, grupo, etc), a sua prioridade, o seu estado, e muitas outras informações, como periféricos em uso, ficheiros abertos, diretório por omissão, programa em execução, contabilização de recursos, signals pendentes, etc).
Abaixo encontra-se um diagrama que mostra uma simplificação do ciclo de vida de um processo.
Gestão de Interrupções
No capítulo anterior vimos que os processos em modo núcleo são sempre desencadeados por uma interrupção. Ora, então, como é que estas são tratadas?
- Interrupção: É desencadeada uma interrupção. O contexto do processo em execução é guardado na pilha.
- Gestor de Interrupções: Identifica a interrupção (agulhagem).
- Rotina de Serviço da Interrupção: É feito o tratamento da interrupção.
- copia registos da pilha atual para o contexto do processo (na tabela de processos);
- corre o código específico à interrupção, possivelmente alterando o estado dos processos;
- invoca o despacho para que este escolha outro processo para executar.
- Despacho: Volta-se a colocar um processo em execução, e o seu contexto é carregado.
- copia o contexto hardware do processo que estava em execução quando a interrupção foi registada para o respetivo descritor (entrada na tabela de processos);
- escolhe um processo para executar (vamos ver como a seguir);
- carrega o contexto hardware do processo escolhido no processador;
- transfere o controlo para o novo processo, colocando o seu PC na pilha. Desta forma, o RTI é enganado a "voltar" (return) para o processo "errado".
- Retorno da Interrupção (RTI): Saída do modo núcleo, para o processo determinado pelo despacho.
Chamadas de Sistema
As chamadas a sistema estão estruturadas em duas entidades funcionais:
- Rotina de Interface: faz parte do código do utilizador e é executada por este. Usa trap para invocar a função do núcleo;
- Função do Núcleo: faz parte do código do núcleo e é esta que executa a operação solicitada pelo utilizador.
Este sistema garante:
- Proteção: o código das funções sistema está residente no núcleo e não pode ser acedido pelos processo em modo utilizador;
- Uniformidade: as funções sistema são partilhadas por todos os processos;
- Flexibilidade: o SO pode ser modificado transparentemente desde que não altere a interface.
Duas Pilhas para Utilizador e Núcleo
Quando o CPU comuta de um processo em modo utilizador tem de:
- mudar o espaço de endereçamento do processo utilizador para o espaço de endereçamento do núcleo;
- mudar da pilha do utilizador para a pilha núcleo do processo. Esta pilha é utilizada a partir do momento em que o processo muda de modo utilizador para modo núcleo e está sempre vazia antes disso.
O uso de pilhas distintas para execução em modo núcleo e em modo utilizador é uma medida de segurança que impede que processos tenham acesso a informação privilegiada do núcleo.
Considere-se a seguinte situação (assumindo que há uma pilha por processo):
Num processo multi-tarefa, uma tarefa faz uma chamada sistema.
Quando a rotina núcleo se executa, coloca variáveis locais das funções núcleo na pilha do processo.
Enquanto isto acontece, outras tarefas deste processo podem estar a correr noutros processadores.
Então, pode acontecer que outras tarefas acedam e corrompam a pilha da tarefa que fez chamada sistema, corrompendo variáveis locais usadas pelas rotinas do núcleo.
Usar uma pilha quando o processo está em modo utilizador e outra pilha quando está em modo núcleo protege os recursos essenciais deste tipo de situações.
Scheduling (Escalonamento)
Damos o nome de escalonamento (ou em inglês, scheduling) ao conceito de definir que processo é que tem acesso a que CPU em cada momento. Para o nosso escalonamento ser o melhor possível, é necessário definir métricas para um bom escalonamento. Estas podem ser:
- Débito (throughput): maximizar número de jobs por hora;
- Turn around time: minimizar tempo entre a submissão do job e a obtenção do resultado;
- Utilização de CPU: maximizar percentagem de tempo de uso do processador;
- Responsividade: responder o mais rapidamente possível aos eventos desencadeados por utilizadores;
- Deadlines: garantir que um certo job acaba antes de um certo deadline;
- Previsibilidade: garantir que os conteúdos são carregados pelo menos a uma dada velocidade. Importante, por exemplo, para conteúdos de multimédia.
Vamos então analisar várias políticas de escalonamento, e ver quais as suas vantagens e desvantagens.
Round-Robin
Pretende que todos os processos executáveis tenham acesso ao CPU ciclicamente.
Faz-se isso dispondo os processos executáveis numa FIFO. Sempre que o CPU está disponível, o elemento na frente da FIFO recebe o CPU durante um quantum ou time-slice.
Isto é, nenhum processo será executado (de seguida) mais do que um dado período de tempo consecutivo.
O processo perde o CPU quando:
- o seu quantum acaba - o processo é reinserido no fim da fila;
- chama uma syscall que o bloqueia - o processo é reinserido no fim da fila quando é desbloqueado;
- termina.
Esta política tem a desvantagem de poder causar elevados tempos de resposta, principalmente em situações de congestionamento. Nomeadamente, se houver processos que exijam muito CPU, e outros que sejam mais I/O intensivos, devemos dar mais prioridade aos do segundo tipo (pois são pouco exigentes do CPU e necessitam de resposta rápida).
Multi-lista
É guardada uma multi-lista, em que cada lista tem processos com uma dada prioridade.
Processos mais prioritários recebem CPU primeiro. A prioridade de um processo pode ser fixa ou dinâmica.
Note-se que um sistema que tenha apenas prioridades fixas sujeita-se a que os processos menos prioritários nunca recebam CPU,
enquanto que prioridades dinâmicas permitem ir tornando os processos que não recebem CPU há mais tempo mais prioritárias.
Esta política permite ainda atribuir quantum diferentes a prioridades diferentes.
Preempção
O conceito de preempção consiste em retirar o CPU ao processo em execução logo que haja um mais prioritário.
Isto permite melhorar o tempo de reação a processos mais prioritários. No entanto, se houver um influxo frequente de processos mais prioritários,
esta política pode dar lugar a mudanças frequentes de contexto, que "desperdiçam" tempo de CPU (que pode e deve ser usado a responder aos processos).
É então aplicada pseudo-preempção: o processo perde o CPU para o mais prioritário, apenas se já tiver utilizado o CPU durante um tempo mínimo.
Os escalonadores hoje em dia:
- usam multi-filas com prioridades dinâmicas e fixas;
- são pseudo-preemptivos com quantum variável;
- atuam sobre tarefas e não processos (sendo um processo um conjunto de uma ou mais tarefas).
Escalonamento Multicore
Tudo o que foi falado até aqui só diz respeito a escalonamento para um só processador.
Em processadores multi-core, o gestor de processos deve ter mais preocupações, como por exemplo, manter tarefas respetivas ao mesmo processo no mesmo CPU, mas também manter uma carga balanceada pelos vários cores.
Políticas respetivas a esta gestão não são abordadas nesta cadeira.
Gestor de Processos no Unix
Contexto dos processos em Unix
Em Unix, o contexto dos processos é dividido em duas estruturas:
-
A estrutura proc, que contém a informação do processo que tem de estar disponível (em RAM), mesmo quando o processo não está em execução, nomeadamente, informação necessária para o escalonamento e funcionamento de signals.
p_stat- estado do processo;p_pri- prioridade do processo;p_sig- sinais enviados ao processo;p_time- tempo que está em memória;p_cpu- tempo de utilização;p_pid- identificador do processo;p_ppid- identificador do pai do processo.
-
A estrutura u (user), que contém a restante informação que só é necessária quando o processo está em execução, podendo estar em disco quando o processo não está em execução.
- registos do processador;
- pilha do núcleo;
- códigos de proteção (
uid,gid); - referência ao diretório corrente e por omissão;
- tabela de ficheiros abertos;
- apontador para a estrutura proc;
- parâmetros da função sistema em execução.
A existência destas duas estruturas era principalmente relevante nas primeiras versões do Unix, que corriam em máquinas com 50KB de RAM.
Diagrama de Estados do Unix (ligeiramente simplificado)
Escalonamento em Unix
Em Unix há dois tipos de prioridades:
- Prioridades para processos em modo utilizador:
- vão de 0 (mais prioritário) a N (menos prioritário);
- são calculadas dinamicamente em função do tempo de processador utilizado;
- escalonamento (quase) preemptivo.
- Prioridades para processos em modo núcleo:
- têm valores negativos (quanto mais negativo, mais prioritário);
- são fixas, consoante o acontecimento que o processo está a tratar;
- são sempre mais prioritárias que os processos em modo utilizador.
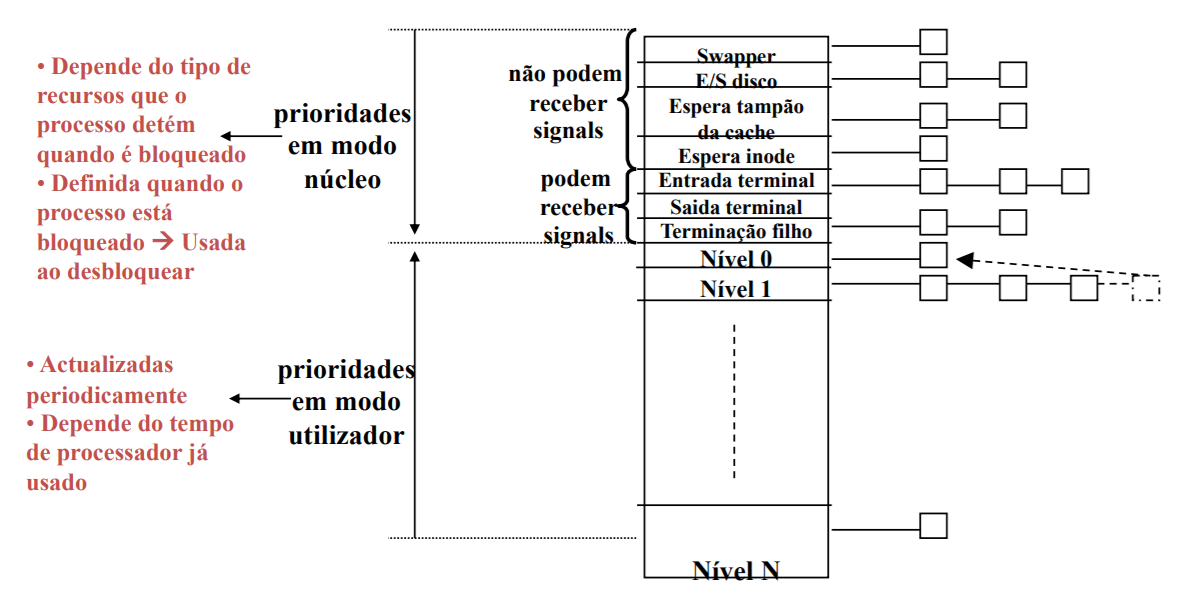
As prioridades do utilizador seguem o seguinte algoritmo:
- o CPU é sempre atribuído ao processo mais prioritário durante um quantum de 100ms (5 "ticks" do relógio);
- Round-Robin entre os processos mais prioritários;
- A cada segundo (50 "ticks") as prioridades são recalculadas de acordo com a seguinte fórmula:
Isto permite ir "esquecendo" progressivamente os usos mais antigos do CPU.
O Unix suporta ainda as seguintes chamadas de sistema:
nice(int val): Muda o valornicede um processo.- Adiciona o valor
valaoniceatual do processo. Assim sendo este processo irá tornar-se menos prioritário, no caso devalser positivo. - Apenas superutilizador pode invocar com
valnegativo. Tornando o processo mais prioritário;
- Adiciona o valor
getpriority(int which, int id): retorna prioridade de um processo ou grupo de processos;setpriority(int which, int id, int prio): altera prioridade do processo ou grupo de processos.
O Gestor de Processos em Unix recalcula a prioridade de todos os processos a cada segundo, pelo que é pouco eficiente quando há muitos processos.
Gestor de Processos no Linux
O Gestor de Processos em Linux tenta resolver o problema encontrado no Gestor de Processos do Unix.
Para isso, divide o tempo em épocas.
Uma época acaba quando todos os processos usaram o seu quantum disponível ou estão bloqueados. No início de cada época, é atribuído a cada processo um quantum e uma prioridade da seguinte forma:
Sendo que o valor do quantum pode ser mudado com chamadas de sistema.
Ao contrário do Unix, as prioridades mais importantes são as com valor mais elevado. No entanto, tal como no Unix, o processo mais prioritário é sempre escolhido primeiro.
Completely Fair Scheduler (CFS)
O CFS é o scheduler usado desde 2007 pelo Linux (o que vimos agora foi entretanto abandonado).
Cada processo tem um atributo vruntime que representa o tempo acumulado de execução em modo utilizador do processo.
Quando o processo perde CPU, o seu vruntime é incrementado com o tempo executado nesse quantum.
Temos que o processo mais prioritário é o com vruntime mínimo. Um novo processo entra com vruntime igual ao mínimo entre o vruntime dos processos ativos.
Os processos são guardados numa red-black tree ordenada por vruntime, que permite encontrar o processo mais prioritário em O(log n) em vez de O(n).
É ainda possível definir prioridades estáticas superiores às dinâmicas (modo utilizador) em contexto real-time ("soft", no sentido que não é 100% real-time). Para isto, são necessários privilégios de núcleo.
Operações Asseguradas pelo Gestor de Processos em POSIX
A cadeira acha mais importante falar destas operações, para os mais curiosos, podem consultar a spec do POSIX.
fork()
A operação fork() reserva uma entrada na tabela proc (Unix), verifica se o utilizador não excedeu o número máximo de subprocessos e atribui um valor ao pid (normalmente um incremento de um inteiro mantido pelo núcleo).
De seguida, copia o contexto do processo pai: como a região de código é partilhada, apenas é incrementado o contador do número de utilizadores que acedem a essa região, as restantes regiões são copiadas.
Finalmente, é retornado o pid do novo processo ao processo pai, e zero ao filho (esses valores são colocados nas pilhas respetivas).

Curiosidades
Matéria não avaliada.
Porque o fork não é uma boa ideia e porque deve ser evitado usar. (link)
Em Linux, há um processo que junta páginas iguais de processos diferentes para poupar memória a posteriori chamado KSM - Kernel Samepage Merging
Basicamente o núcleo varre ocasionalmente as páginas no sistema, se vir que existem 2 páginas iguais, ativa o bit CoW e mete o outro processso a usar esta página, apagando a outra, ganhando espaço em memória.
exit()
A operação exit() termina um processo, executando as funções registadas pelo atexit (esta não precisa de ajuda do núcleo para ser executada), libertando todos os recursos (ficheiro, diretoria corrente, regiões de memória).
De seguida actualiza o ficheiro que regista a utilização do processador, memória e I/O.
Finalmente, envia signal death of child (SIGCHILD) ao processo pai (que por omissão é ignorado) e mantém o filho no estado zombie, até que o pai o encontre (obtendo informação sobre a terminação do filho).
wait()
O operação wait() procura por filhos zombie:
- se não há filho zombie, o pai fica bloqueado;
- se não há filhos, a função retorna imediatamente.
O pid do filho e estado do exit são retornados através do wait e a estrutura
procdo filho é finalmente libertada.
exec()
A funçao exec() executa um novo programa no âmbito de um processo já existente:
- primeiro, verifica se o ficheiro existe e é executável;
- copia os argumentos da chamada exec da pilha do utilizador para o núcleo (pois o contexto utilizador irá ser destruído);
- liberta as regiões de dados e pilha ocupadas pelo processo;
- reserva novas regiões de memória;
- carrega o ficheiro de código executável;
- copia os argumentos da pilha do núcleo para a pilha do utilizador.
O processo fica no estado executável e o contexto software do mesmo mantém-se inalterado.
signal()
Se o processo tem rotina de tratamento associada ao signal, o núcleo regista no contexto do processo que o signal ocorreu.
Antes do processo receber de novo execução, o despacho salta para a rotina de tratamento do signal.
pthread_mutex
Fechar e abrir mutex's são chamadas de sistema. A espera bloqueante é conseguida com ajuda do núcleo. Isto já foi abordado nos resumos de Implementação de um Mutex